
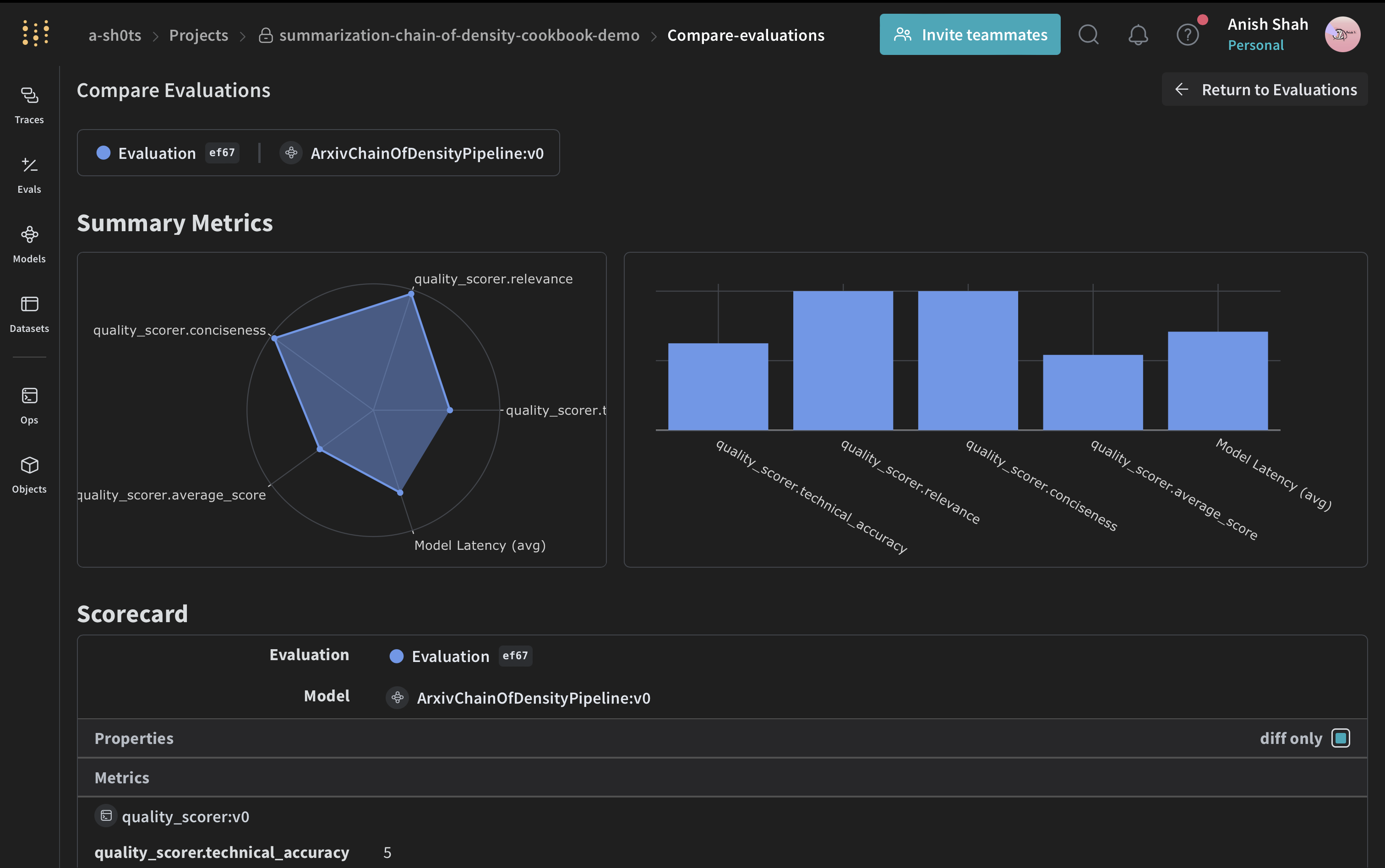
Summarization using Chain of Density
Summarizing complex technical documents while preserving crucial details is a challenging task. The Chain of Density (CoD) summarization technique offers a solution by iteratively refining summaries to be more concise and information-dense. This guide demonstrates how to implement CoD using Weave for tracking and evaluating the application.
What is Chain of Density Summarization?
![]()
Chain of Density (CoD) is an iterative summarization technique that produces increasingly concise and information-dense summaries. It works by:
- Starting with an initial summary
- Iteratively refining the summary, making it more concise while preserving key information
- Increasing the density of entities and technical details with each iteration
This approach is particularly useful for summarizing scientific papers or technical documents where preserving detailed information is crucial.
Why use Weave?
In this tutorial, we'll use Weave to implement and evaluate a Chain of Density summarization pipeline for ArXiv papers. You'll learn how to:
- Track your LLM pipeline: Use Weave to automatically log inputs, outputs, and intermediate steps of your summarization process.
- Evaluate LLM outputs: Create rigorous, apples-to-apples evaluations of your summaries using Weave's built-in tools.
- Build composable operations: Combine and reuse Weave operations across different parts of your summarization pipeline.
- Integrate seamlessly: Add Weave to your existing Python code with minimal overhead.
By the end of this tutorial, you'll have created a CoD summarization pipeline that leverages Weave's capabilities for model serving, evaluation, and result tracking.
Set up the environment
First, let's set up our environment and import the necessary libraries:
!pip install -qU anthropic weave pydantic requests PyPDF2 set-env-colab-kaggle-dotenv
To get an Anthropic API key:
- Sign up for an account at https://www.anthropic.com
- Navigate to the API section in your account settings
- Generate a new API key
- Store the API key securely in your .env file
import io
import os
from datetime import datetime, timezone
import anthropic
import requests
from pydantic import BaseModel
from PyPDF2 import PdfReader
from set_env import set_env
import weave
set_env("WANDB_API_KEY")
set_env("ANTHROPIC_API_KEY")
weave.init("summarization-chain-of-density-cookbook")
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
We're using Weave to track our experiment and Anthropic's Claude model for text generation. The weave.init(<project name>) call sets up a new Weave project for our summarization task.
Define the ArxivPaper model
We'll create a simple ArxivPaper class to represent our data:
# Define ArxivPaper model
class ArxivPaper(BaseModel):
entry_id: str
updated: datetime
published: datetime
title: str
authors: list[str]
summary: str
pdf_url: str
# Create sample ArxivPaper
arxiv_paper = ArxivPaper(
entry_id="http://arxiv.org/abs/2406.04744v1",
updated=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
published=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
title="CRAG -- Comprehensive RAG Benchmark",
authors=["Xiao Yang", "Kai Sun", "Hao Xin"], # Truncated for brevity
summary="Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution...", # Truncated
pdf_url="https://arxiv.org/pdf/2406.04744",
)
This class encapsulates the metadata and content of an ArXiv paper, which will be the input to our summarization pipeline.
Load PDF content
To work with the full paper content, we'll add a function to load and extract text from PDFs:
@weave.op()
def load_pdf(pdf_url: str) -> str:
# Download the PDF
response = requests.get(pdf_url)
pdf_file = io.BytesIO(response.content)
# Read the PDF
pdf_reader = PdfReader(pdf_file)
# Extract text from all pages
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
return text
Implement Chain of Density summarization
Now, let's implement the core CoD summarization logic using Weave operations:
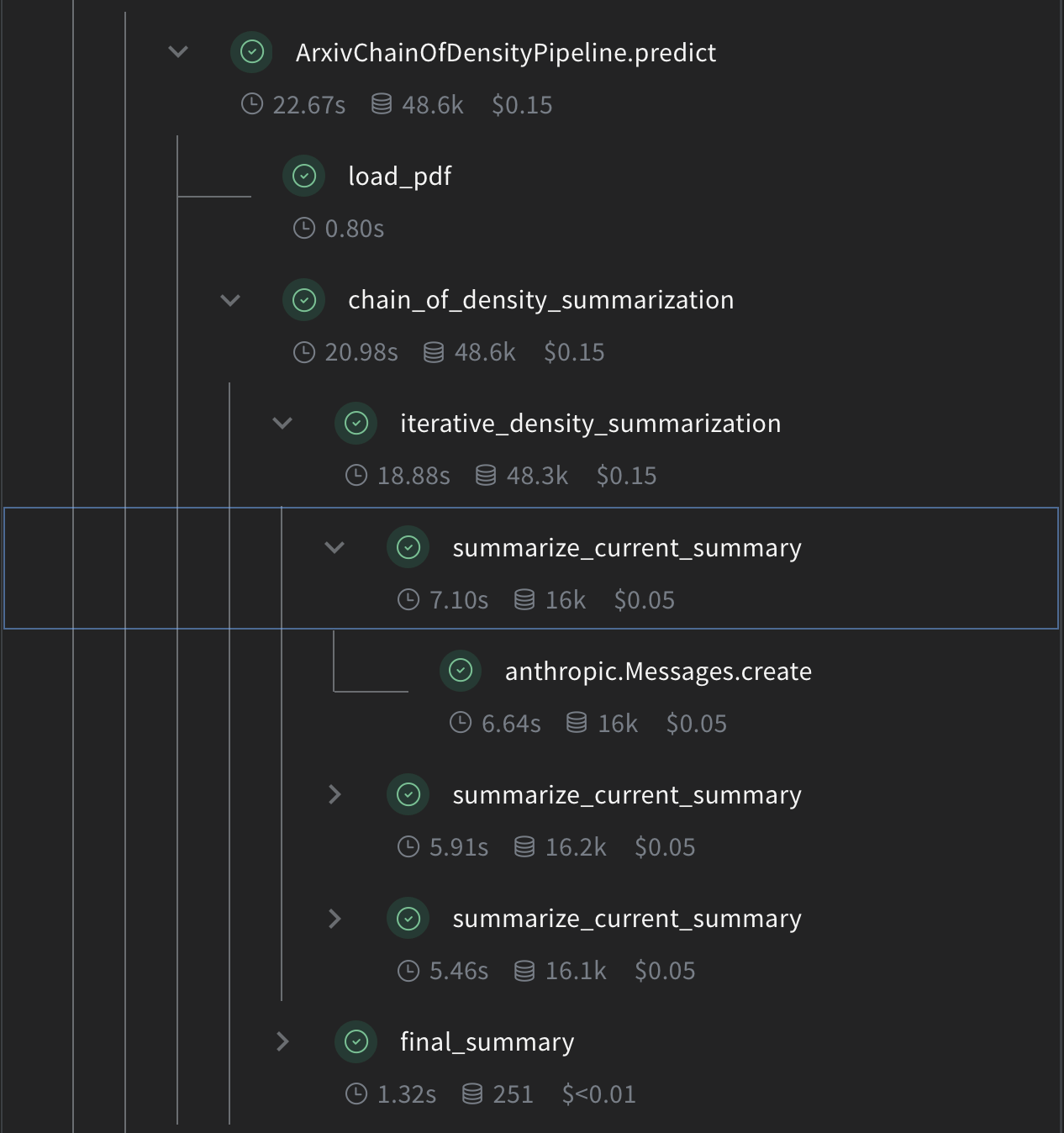
# Chain of Density Summarization
@weave.op()
def summarize_current_summary(
document: str,
instruction: str,
current_summary: str = "",
iteration: int = 1,
model: str = "claude-3-sonnet-20240229",
):
prompt = f"""
Document: {document}
Current summary: {current_summary}
Instruction to focus on: {instruction}
Iteration: {iteration}
Generate an increasingly concise, entity-dense, and highly technical summary from the provided document that specifically addresses the given instruction.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
@weave.op()
def iterative_density_summarization(
document: str,
instruction: str,
current_summary: str,
density_iterations: int,
model: str = "claude-3-sonnet-20240229",
):
iteration_summaries = []
for iteration in range(1, density_iterations + 1):
current_summary = summarize_current_summary(
document, instruction, current_summary, iteration, model
)
iteration_summaries.append(current_summary)
return current_summary, iteration_summaries
@weave.op()
def final_summary(
instruction: str, current_summary: str, model: str = "claude-3-sonnet-20240229"
):
prompt = f"""
Given this summary: {current_summary}
And this instruction to focus on: {instruction}
Create an extremely dense, final summary that captures all key technical information in the most concise form possible, while specifically addressing the given instruction.
"""
return (
anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
.content[0]
.text
)
@weave.op()
def chain_of_density_summarization(
document: str,
instruction: str,
current_summary: str = "",
model: str = "claude-3-sonnet-20240229",
density_iterations: int = 2,
):
current_summary, iteration_summaries = iterative_density_summarization(
document, instruction, current_summary, density_iterations, model
)
final_summary_text = final_summary(instruction, current_summary, model)
return {
"final_summary": final_summary_text,
"accumulated_summary": current_summary,
"iteration_summaries": iteration_summaries,
}
Here's what each function does:
summarize_current_summary: Generates a single summary iteration based on the current state.iterative_density_summarization: Applies the CoD technique by callingsummarize_current_summarymultiple times.chain_of_density_summarization: Orchestrates the entire summarization process and returns the results.
By using @weave.op() decorators, we ensure that Weave tracks the inputs, outputs, and execution of these functions.
Create a Weave Model
Now, let's wrap our summarization pipeline in a Weave Model:
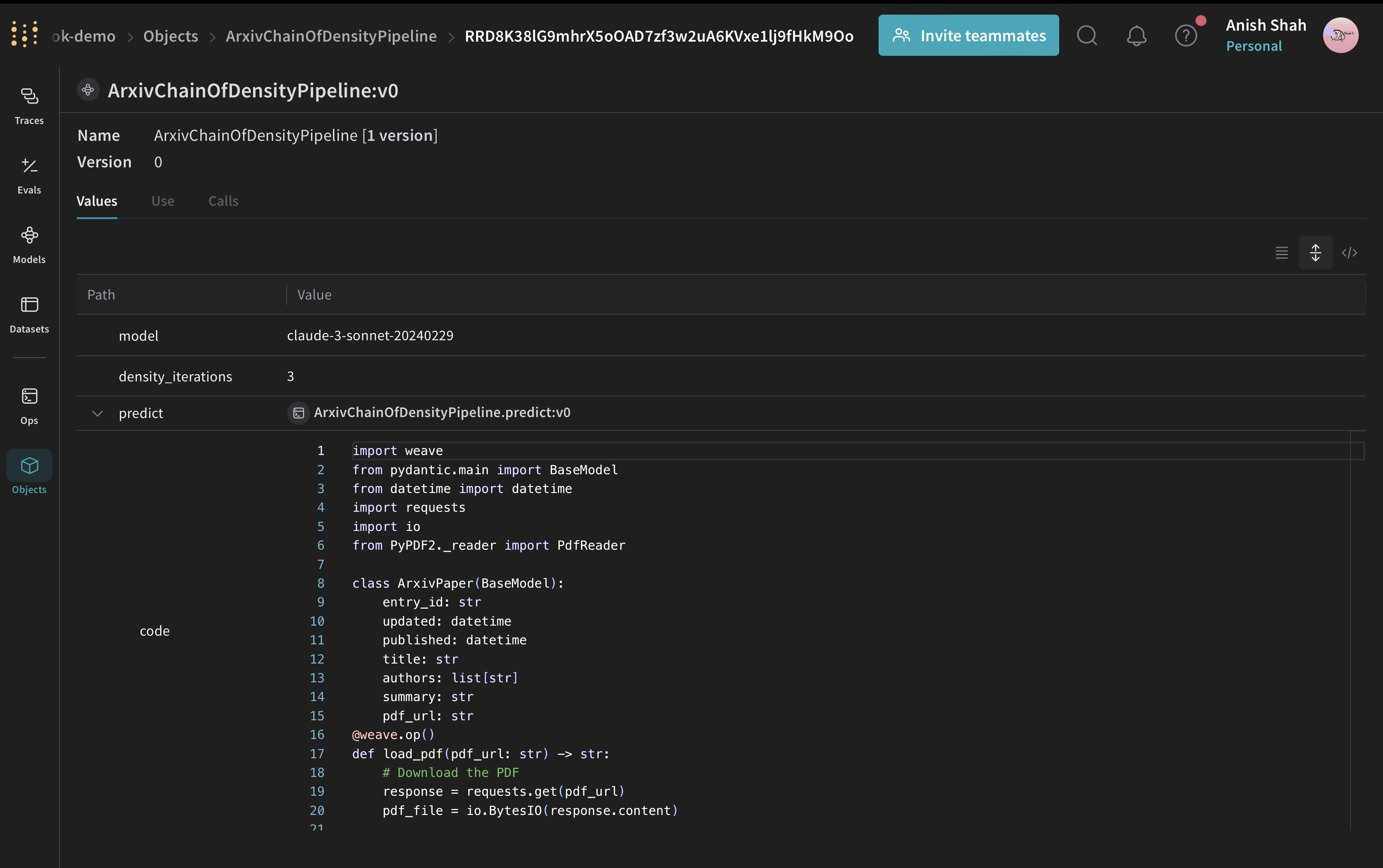
# Weave Model
class ArxivChainOfDensityPipeline(weave.Model):
model: str = "claude-3-sonnet-20240229"
density_iterations: int = 3
@weave.op()
def predict(self, paper: ArxivPaper, instruction: str) -> dict:
text = load_pdf(paper.pdf_url)
result = chain_of_density_summarization(
text,
instruction,
model=self.model,
density_iterations=self.density_iterations,
)
return result
This ArxivChainOfDensityPipeline class encapsulates our summarization logic as a Weave Model, providing several key benefits:
- Automatic experiment tracking: Weave captures inputs, outputs, and parameters for each run of the model.
- Versioning: Changes to the model's attributes or code are automatically versioned, creating a clear history of how your summarization pipeline evolves over time.
- Reproducibility: The versioning and tracking make it easy to reproduce any previous result or configuration of your summarization pipeline.
- Hyperparameter management: Model attributes (like
modelanddensity_iterations) are clearly defined and tracked across different runs, facilitating experimentation. - Integration with Weave ecosystem: Using
weave.Modelallows seamless integration with other Weave tools, such as evaluations and serving capabilities.
Implement evaluation metrics
To assess the quality of our summaries, we'll implement simple evaluation metrics:
import json
@weave.op()
def evaluate_summary(
summary: str, instruction: str, model: str = "claude-3-sonnet-20240229"
) -> dict:
prompt = f"""
Summary: {summary}
Instruction: {instruction}
Evaluate the summary based on the following criteria:
1. Relevance (1-5): How well does the summary address the given instruction?
2. Conciseness (1-5): How concise is the summary while retaining key information?
3. Technical Accuracy (1-5): How accurately does the summary convey technical details?
Your response MUST be in the following JSON format:
{{
"relevance": {{
"score": <int>,
"explanation": "<string>"
}},
"conciseness": {{
"score": <int>,
"explanation": "<string>"
}},
"technical_accuracy": {{
"score": <int>,
"explanation": "<string>"
}}
}}
Ensure that the scores are integers between 1 and 5, and that the explanations are concise.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=1000, messages=[{"role": "user", "content": prompt}]
)
print(response.content[0].text)
eval_dict = json.loads(response.content[0].text)
return {
"relevance": eval_dict["relevance"]["score"],
"conciseness": eval_dict["conciseness"]["score"],
"technical_accuracy": eval_dict["technical_accuracy"]["score"],
"average_score": sum(eval_dict[k]["score"] for k in eval_dict) / 3,
"evaluation_text": response.content[0].text,
}
These evaluation functions use the Claude model to assess the quality of the generated summaries based on relevance, conciseness, and technical accuracy.
Create a Weave Dataset and run evaluation
To evaluate our pipeline, we'll create a Weave Dataset and run an evaluation:
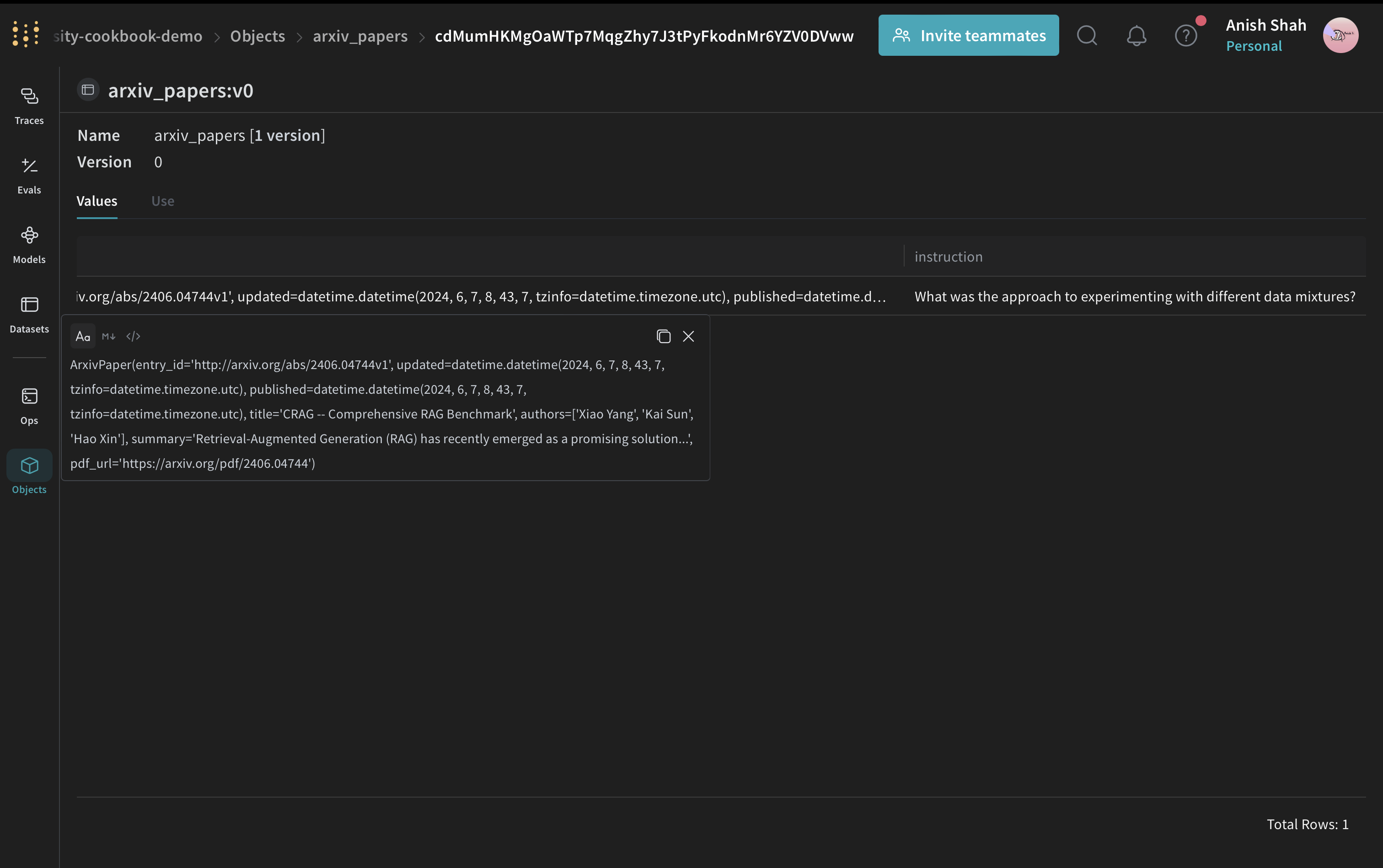
# Create a Weave Dataset
dataset = weave.Dataset(
name="arxiv_papers",
rows=[
{
"paper": arxiv_paper,
"instruction": "What was the approach to experimenting with different data mixtures?",
},
],
)
weave.publish(dataset)
For our evaluation, we'll use an LLM-as-a-judge approach. This technique involves using a language model to assess the quality of outputs generated by another model or system. It leverages the LLM's understanding and reasoning capabilities to provide nuanced evaluations, especially for tasks where traditional metrics may fall short.
![]()
# Define the scorer function
@weave.op()
def quality_scorer(instruction: str, output: dict) -> dict:
result = evaluate_summary(output["final_summary"], instruction)
return result
# Run evaluation
evaluation = weave.Evaluation(dataset=dataset, scorers=[quality_scorer])
arxiv_chain_of_density_pipeline = ArxivChainOfDensityPipeline()
results = await evaluation.evaluate(arxiv_chain_of_density_pipeline)
This code creates a dataset with our sample ArXiv paper, defines a quality scorer, and runs an evaluation of our summarization pipeline.
Conclusion
In this example, we've demonstrated how to implement a Chain of Density summarization pipeline for ArXiv papers using Weave. We've shown how to:
- Create Weave operations for each step of the summarization process
- Wrap the pipeline in a Weave Model for easy tracking and evaluation
- Implement custom evaluation metrics using Weave operations
- Create a dataset and run an evaluation of the pipeline
Weave's seamless integration allows us to track inputs, outputs, and intermediate steps throughout the summarization process, making it easier to debug, optimize, and evaluate our LLM application. You can extend this example to handle larger datasets, implement more sophisticated evaluation metrics, or integrate with other LLM workflows.
View Full Report on W&B