
🏃♀️ Quickstart
Get started using Weave to:
- Log and debug language model inputs, outputs, and traces
- Build rigorous, apples-to-apples evaluations for language model use cases
- Organize all the information generated across the LLM workflow, from experimentation to evaluations to production
See the full Weave documentation here.
🪄 Install weave library and login
Start by installing the library and logging in to your account.
In this example, we're using openai so you should add an openai API key.
%%capture
!pip install weave openai set-env-colab-kaggle-dotenv
# Set your OpenAI API key
from set_env import set_env
# Put your OPENAI_API_KEY in the secrets panel to the left 🗝️
_ = set_env("OPENAI_API_KEY")
# os.environ["OPENAI_API_KEY"] = "sk-..." # alternatively, put your key here
PROJECT = "weave-intro-notebook"
Track inputs & outputs of functions
Weave allows users to track function calls: the code, inputs, outputs, and even LLM tokens & costs! In the following sections we will cover:
- Custom Functions
- Vendor Integrations
- Nested Function Calling
- Error Tracking
Note: in all cases, we will:
import weave # import the weave library
weave.init('project-name') # initialize tracking for a specific W&B project
Track custom functions
Add the @weave.op decorator to the functions you want to track
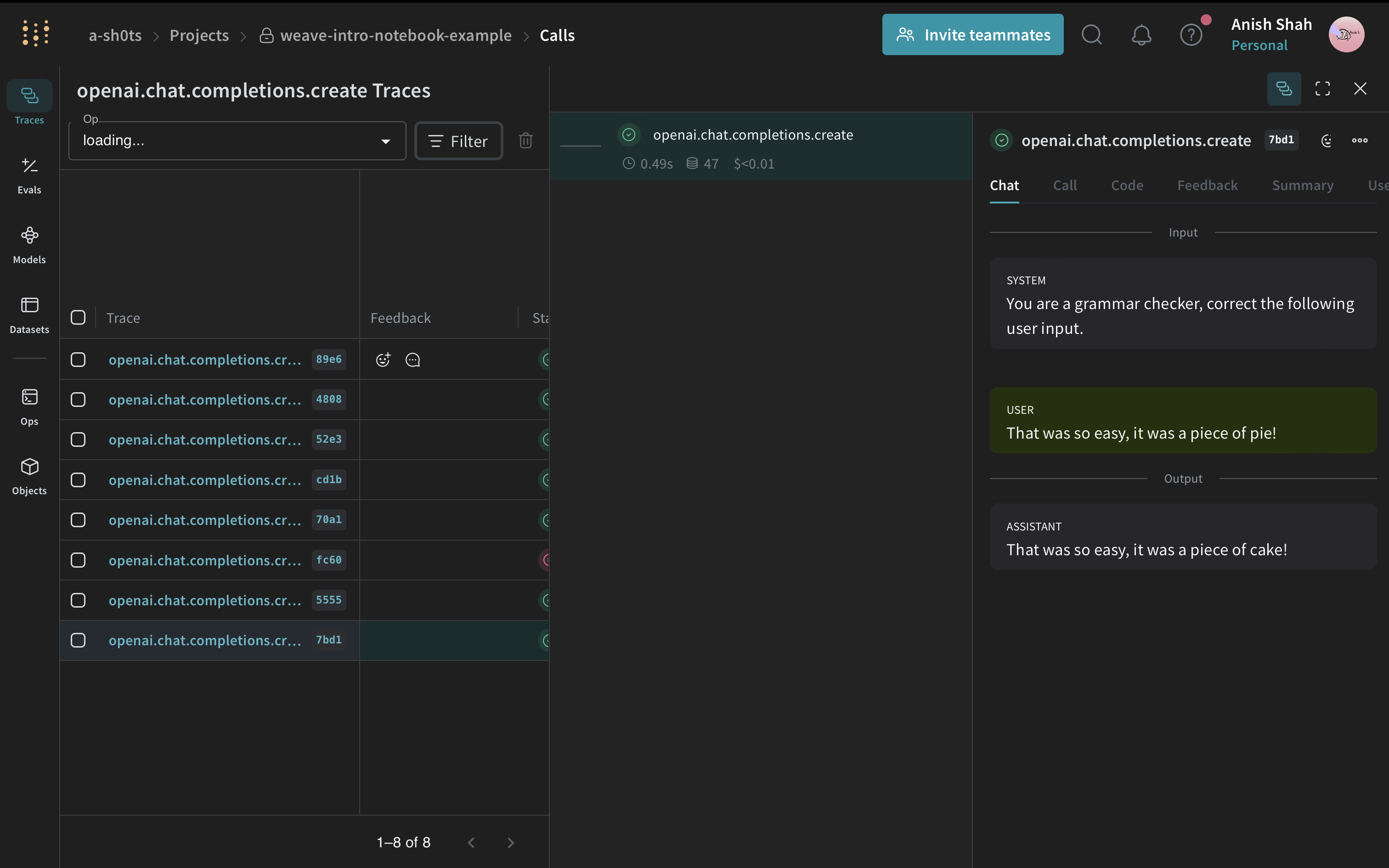
from openai import OpenAI
import weave
weave.init(PROJECT)
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "You are a grammar checker, correct the following user input.",
},
{"role": "user", "content": "That was so easy, it was a piece of pie!"},
],
temperature=0,
)
generation = response.choices[0].message.content
print(generation)
You can find your interactive dashboard by clicking any of the 👆 wandb links above.
Vendor Integrations (OpenAI, Anthropic, Mistral, etc...)
Here, we're automatically tracking all calls to openai. We automatically track a lot of LLM libraries, but it's really easy to add support for whatever LLM you're using, as you'll see below.
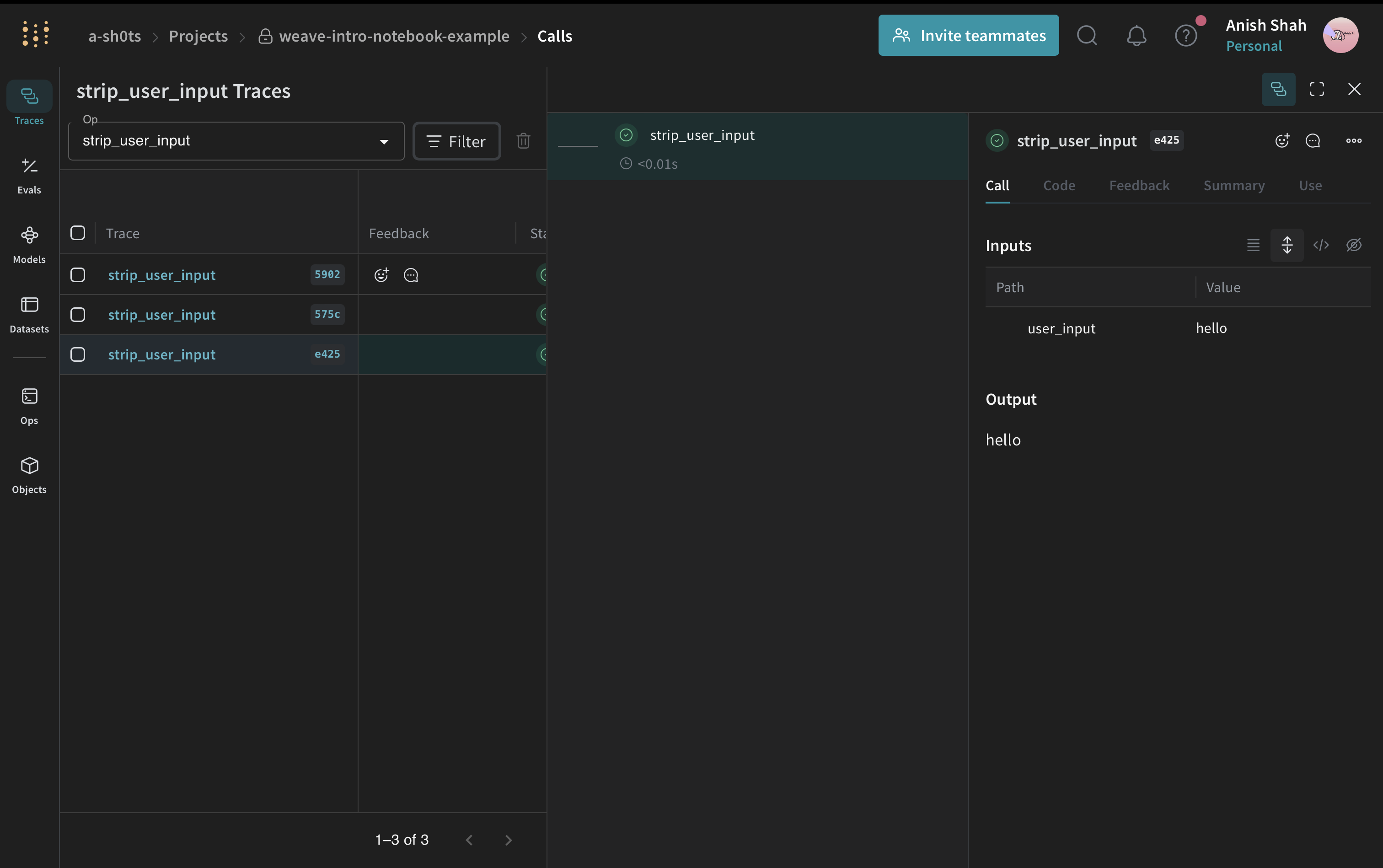
import weave
weave.init(PROJECT)
@weave.op()
def strip_user_input(user_input):
return user_input.strip()
result = strip_user_input(" hello ")
print(result)
After adding weave.op and calling the function, visit the link and see it tracked within your project.
💡 We automatically track your code, have a look at the code tab!
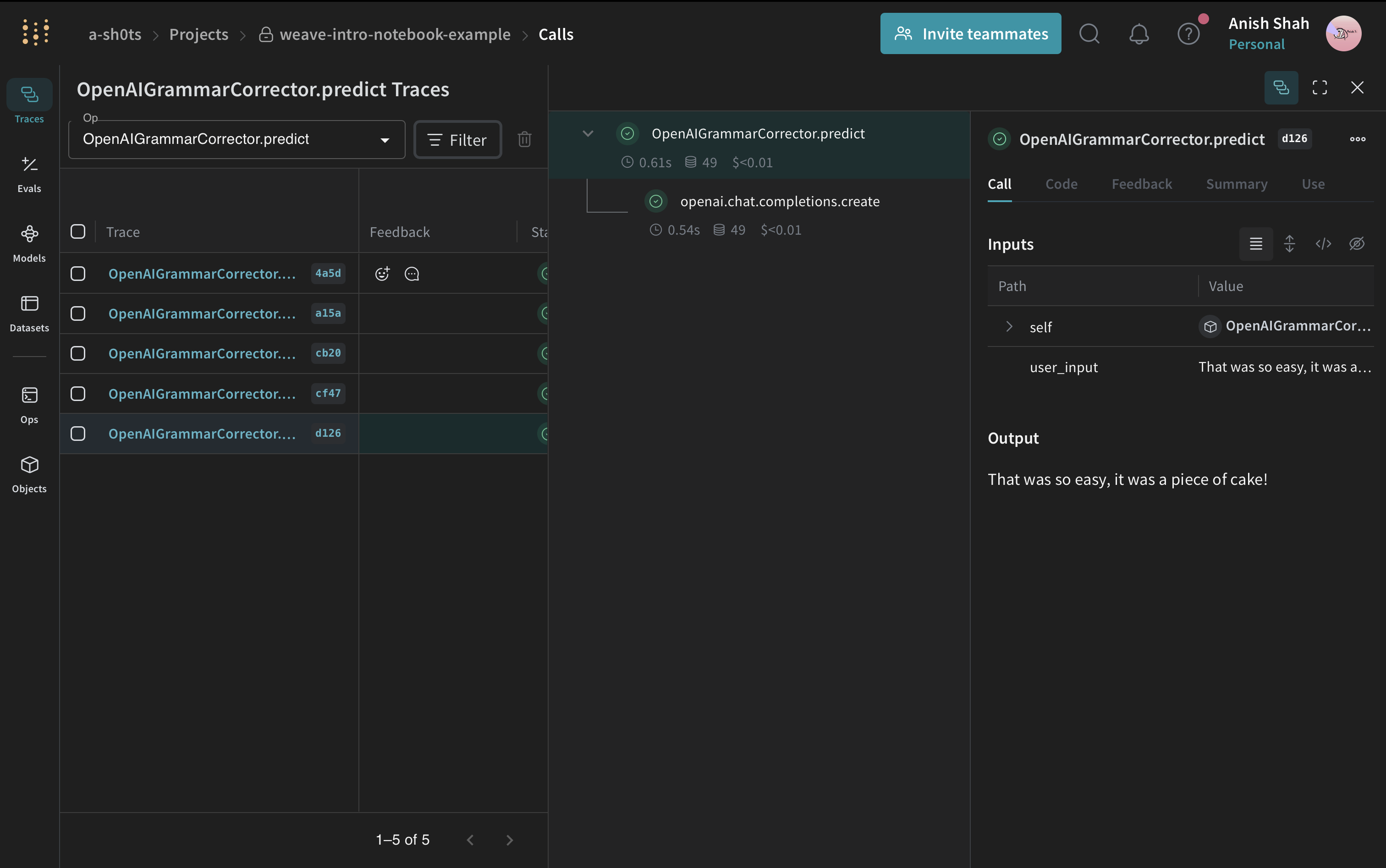
Track nested functions
Now that you've seen the basics, let's combine all of the above and track some deeply nested functions alongside LLM calls.
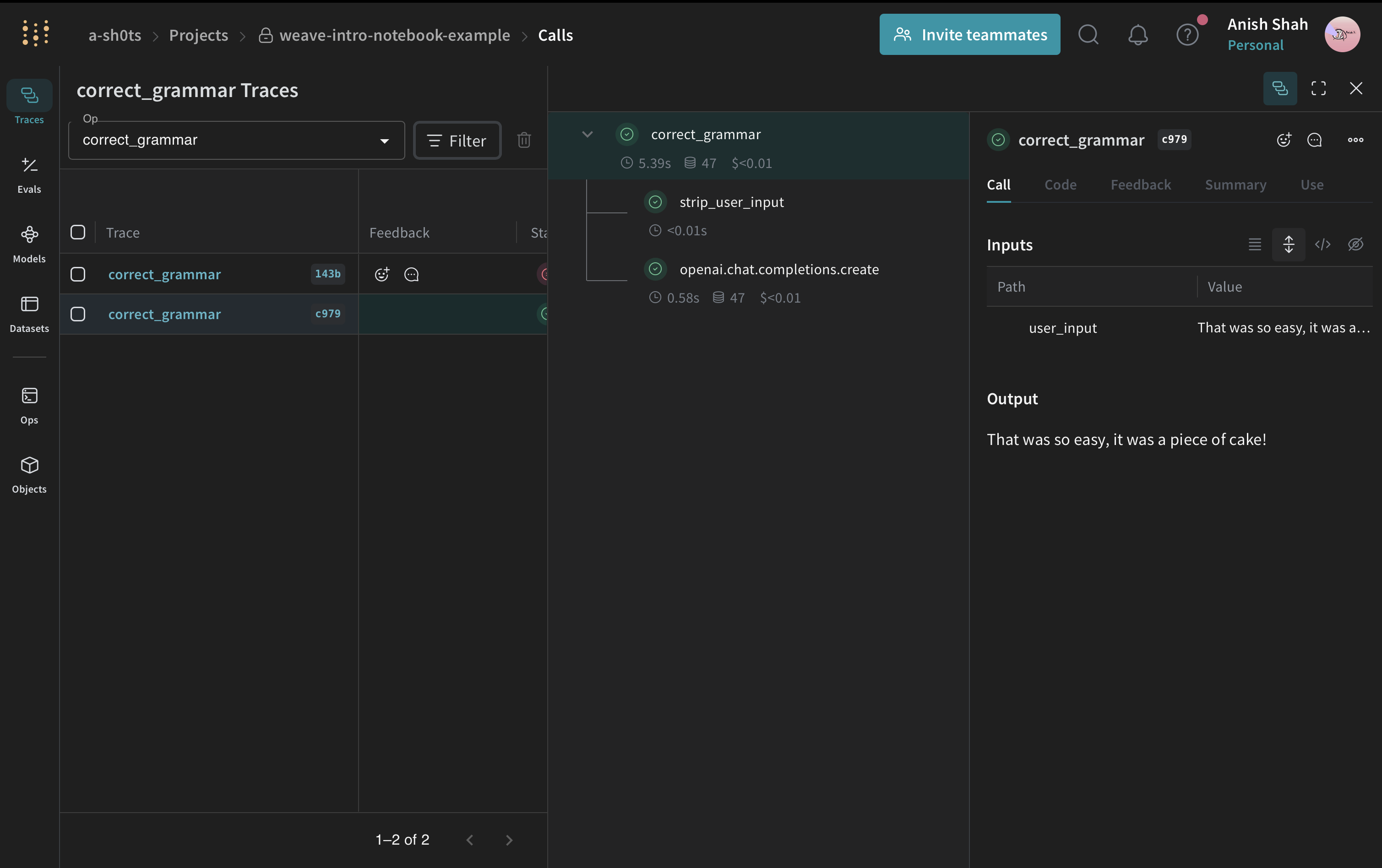
from openai import OpenAI
import weave
weave.init(PROJECT)
@weave.op()
def strip_user_input(user_input):
return user_input.strip()
@weave.op()
def correct_grammar(user_input):
client = OpenAI()
stripped = strip_user_input(user_input)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "You are a grammar checker, correct the following user input.",
},
{"role": "user", "content": stripped},
],
temperature=0,
)
return response.choices[0].message.content
result = correct_grammar(" That was so easy, it was a piece of pie! ")
print(result)
Track Errors
Whenever your code crashes, weave will highlight what caused the issue. This is especially useful for finding things like JSON parsing issues that can occasionally happen when parsing data from LLM responses.
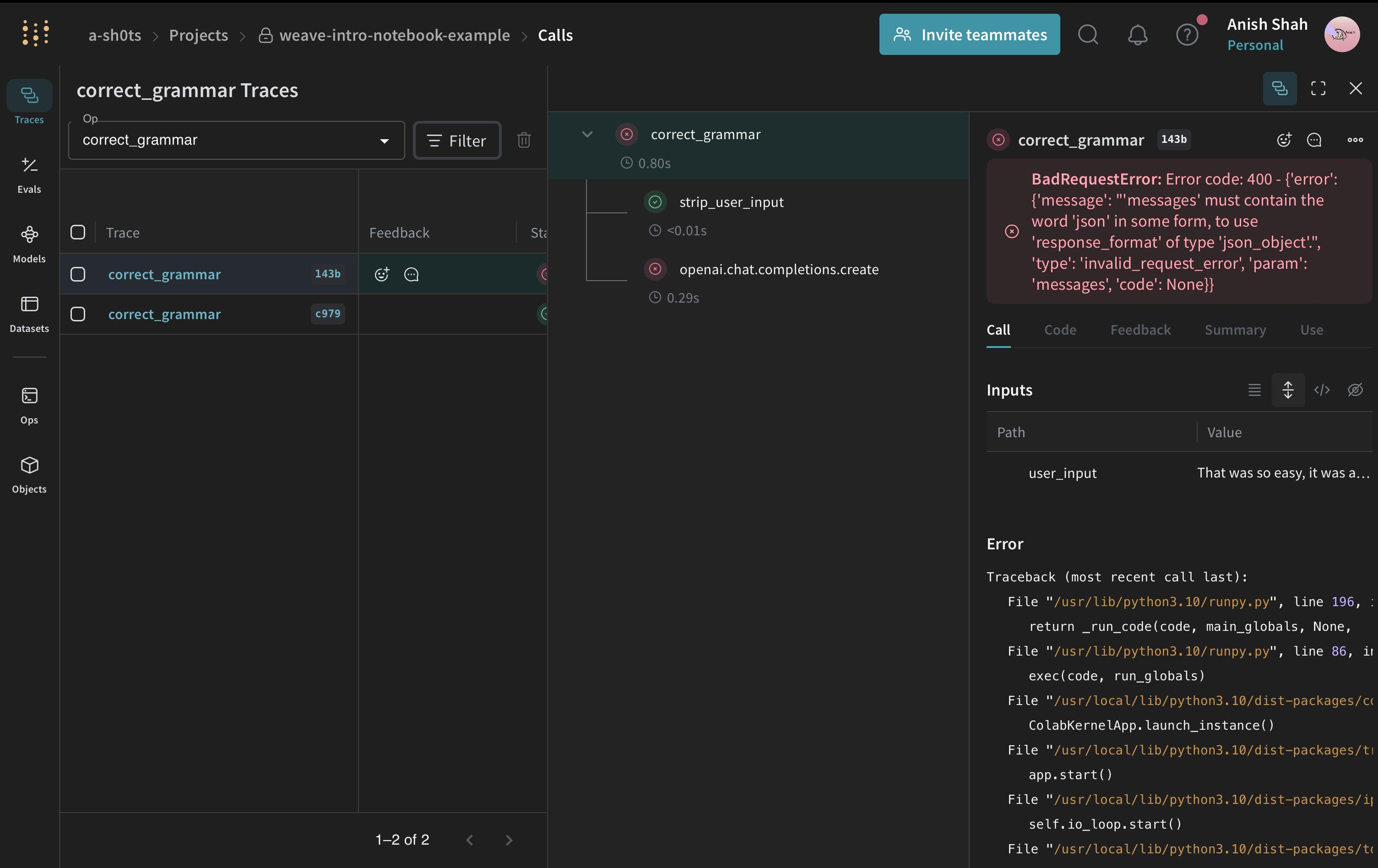
import json
from openai import OpenAI
import weave
weave.init(PROJECT)
@weave.op()
def strip_user_input(user_input):
return user_input.strip()
@weave.op()
def correct_grammar(user_input):
client = OpenAI()
stripped = strip_user_input(user_input)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "You are a grammar checker, correct the following user input.",
},
{"role": "user", "content": stripped},
],
temperature=0,
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
result = correct_grammar(" That was so easy, it was a piece of pie! ")
print(result)
Tracking Objects
Organizing experimentation is difficult when there are many moving pieces. You can capture and organize the experimental details of your app like your system prompt or the model you're using within weave.Objects. This helps organize and compare different iterations of your app. In this section, we will cover:
- General Object Tracking
- Tracking Models
- Tracking Datasets
General Object Tracking
Many times, it is useful to track & version data, just like you track and version code. For example, here we define a SystemPrompt(weave.Object) object that can be shared between teammates
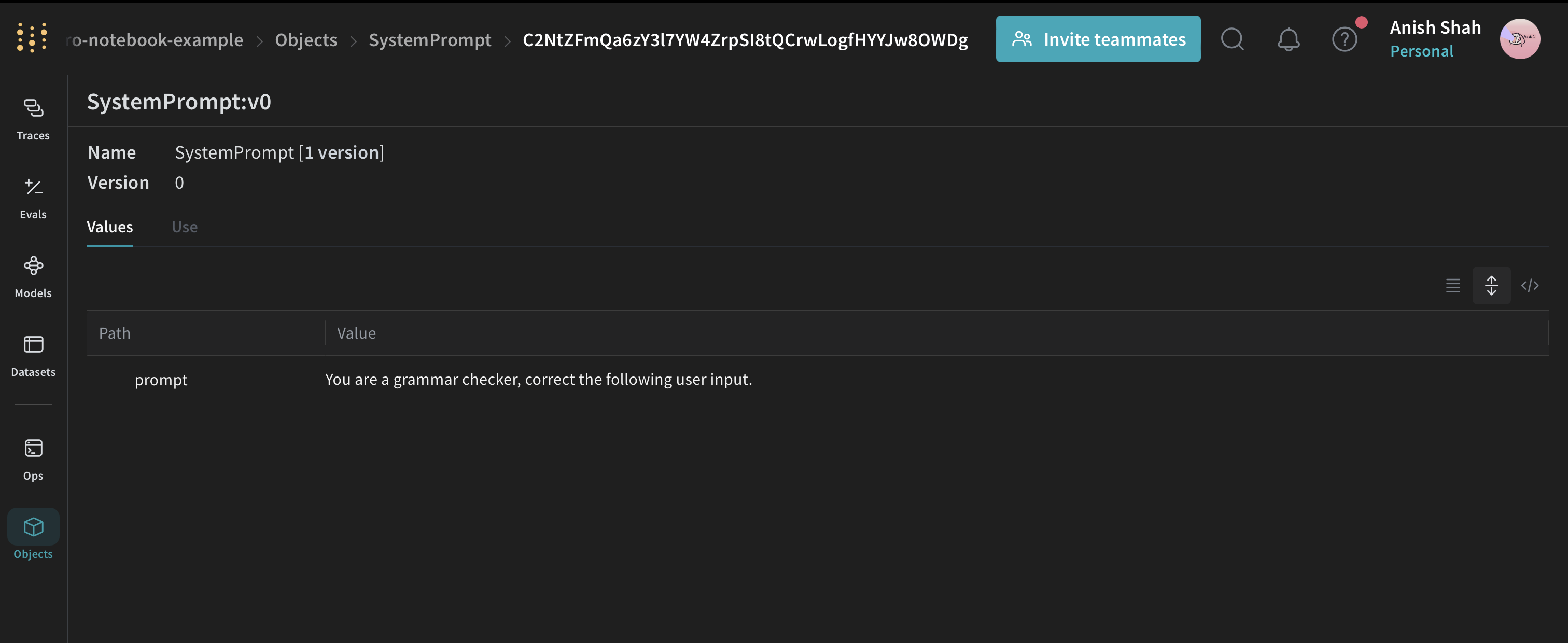
import weave
weave.init(PROJECT)
class SystemPrompt(weave.Object):
prompt: str
system_prompt = SystemPrompt(
prompt="You are a grammar checker, correct the following user input."
)
weave.publish(system_prompt)
Model Tracking
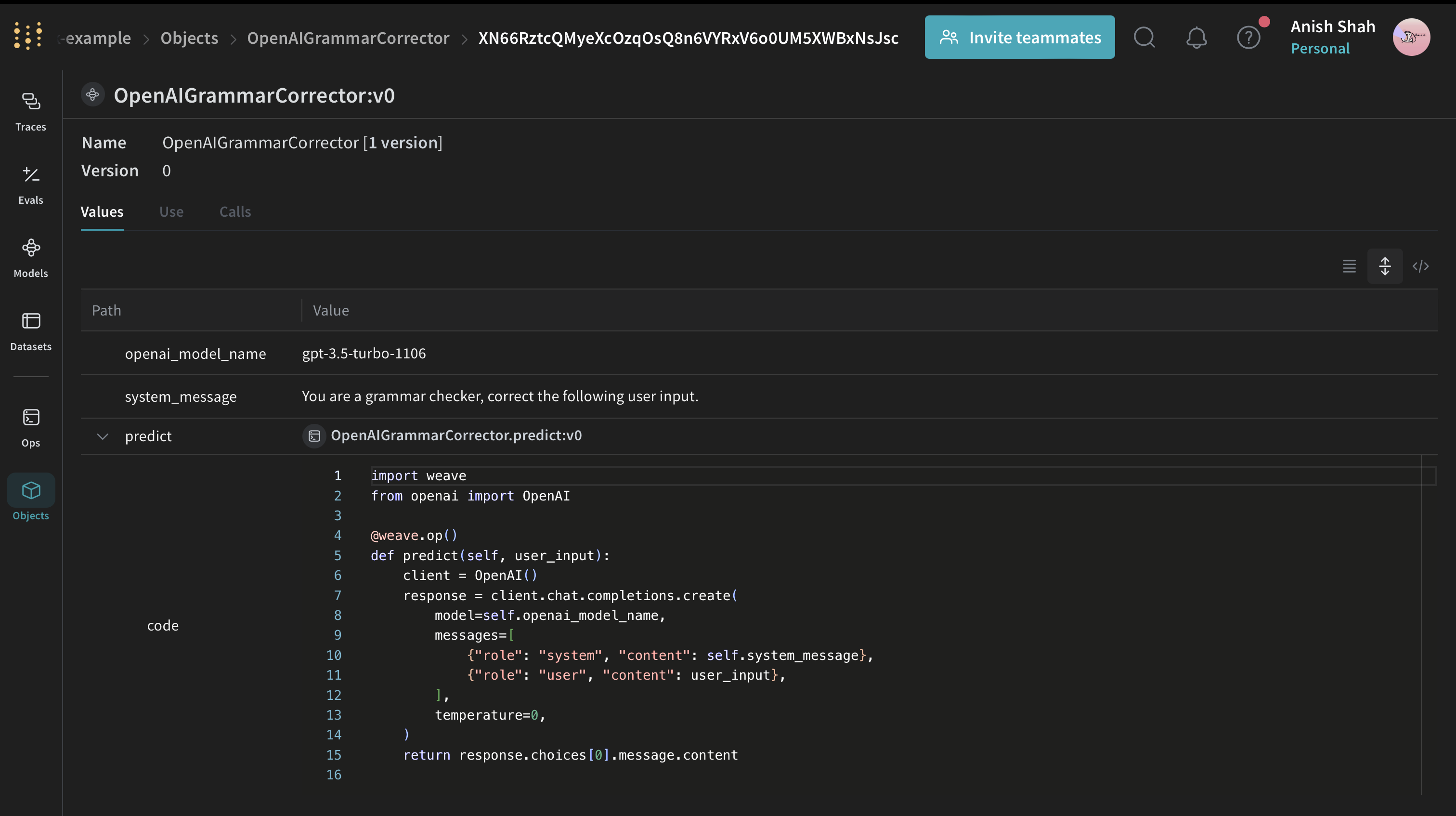
Models are so common of an object type, that we have a special class to represent them: weave.Model. The only requirement is that we define a predict method.
from openai import OpenAI
import weave
weave.init(PROJECT)
class OpenAIGrammarCorrector(weave.Model):
# Properties are entirely user-defined
openai_model_name: str
system_message: str
@weave.op()
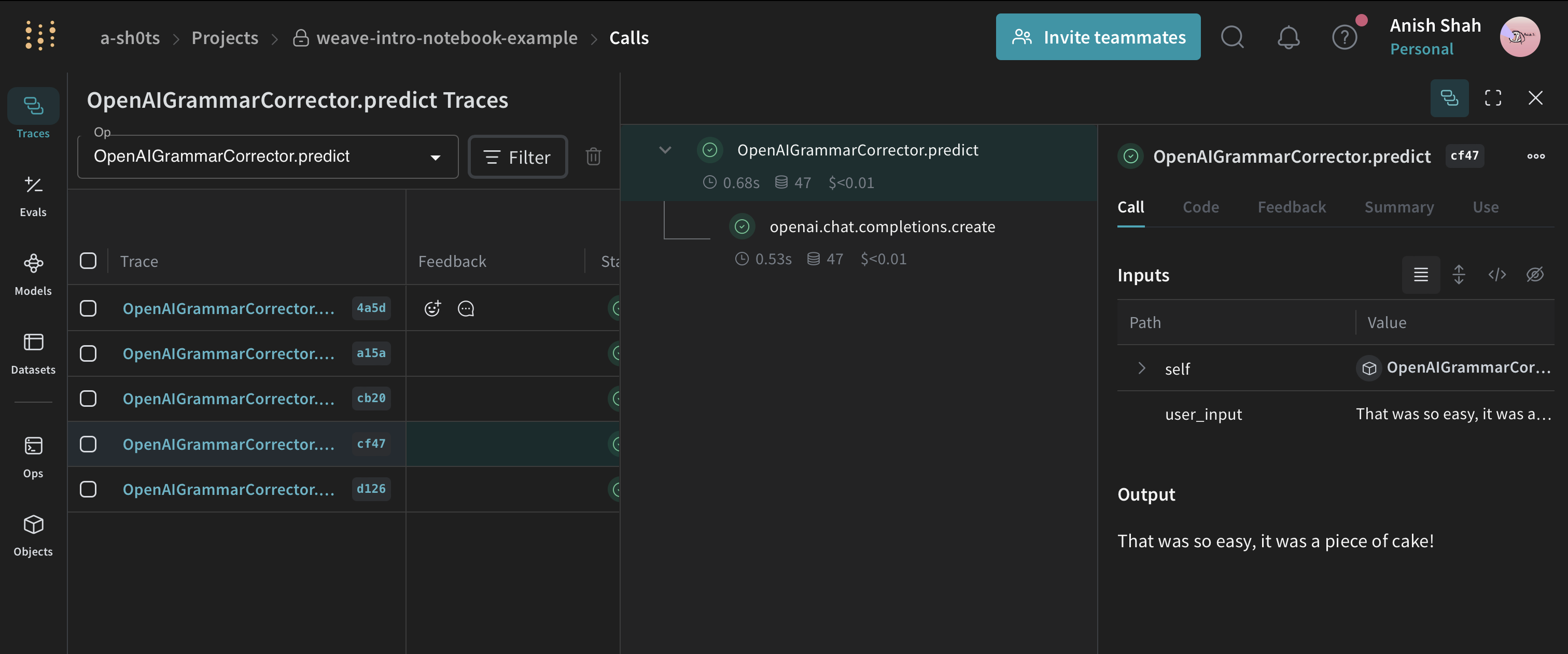
def predict(self, user_input):
client = OpenAI()
response = client.chat.completions.create(
model=self.openai_model_name,
messages=[
{"role": "system", "content": self.system_message},
{"role": "user", "content": user_input},
],
temperature=0,
)
return response.choices[0].message.content
corrector = OpenAIGrammarCorrector(
openai_model_name="gpt-4o-mini",
system_message="You are a grammar checker, correct the following user input.",
)
result = corrector.predict(" That was so easy, it was a piece of pie! ")
print(result)
Dataset Tracking
Similar to models, a weave.Dataset object exists to help track, organize, and operate on datasets
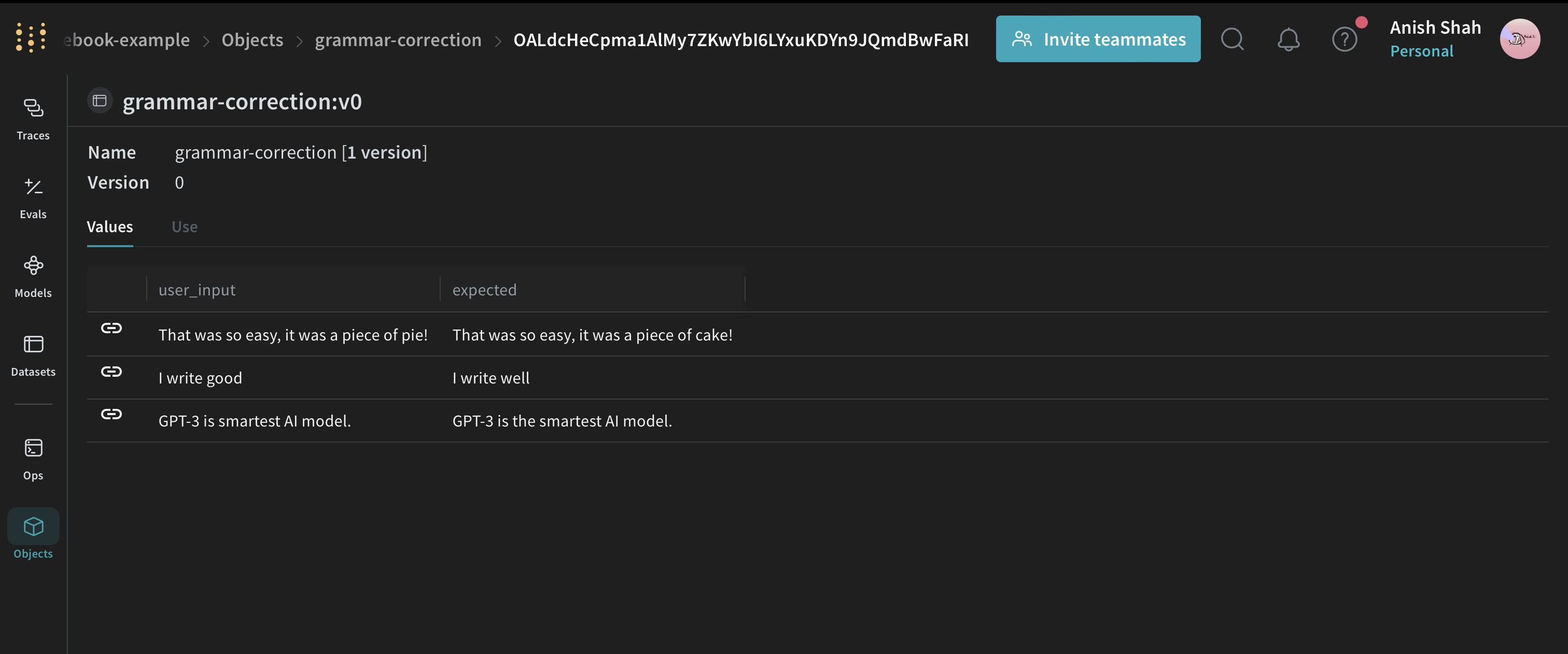
dataset = weave.Dataset(
name="grammar-correction",
rows=[
{
"user_input": " That was so easy, it was a piece of pie! ",
"expected": "That was so easy, it was a piece of cake!",
},
{"user_input": " I write good ", "expected": "I write well"},
{
"user_input": " GPT-4 is smartest AI model. ",
"expected": "GPT-4 is the smartest AI model.",
},
],
)
weave.publish(dataset)
Notice that we saved a versioned GrammarCorrector object that captures the configurations you're experimenting with.
Retrieve Published Objects & Ops
You can publish objects and then retrieve them in your code. You can even call functions from your retrieved objects!
import weave
weave.init(PROJECT)
corrector = OpenAIGrammarCorrector(
openai_model_name="gpt-4o-mini",
system_message="You are a grammar checker, correct the following user input.",
)
ref = weave.publish(corrector)
print(ref.uri())
import weave
weave.init(PROJECT)
# Note: this url is available from the UI after publishing the object!
ref_url = f"weave:///{ref.entity}/{PROJECT}/object/{ref.name}:{ref.digest}"
fetched_collector = weave.ref(ref_url).get()
# Notice: this object was loaded from remote location!
result = fetched_collector.predict("That was so easy, it was a piece of pie!")
print(result)
Evaluation
Evaluation-driven development helps you reliably iterate on an application. The Evaluation class is designed to assess the performance of a Model on a given Dataset or set of examples using scoring functions.
See a preview of the API below:
import weave
from weave import Evaluation
# Define any custom scoring function
@weave.op()
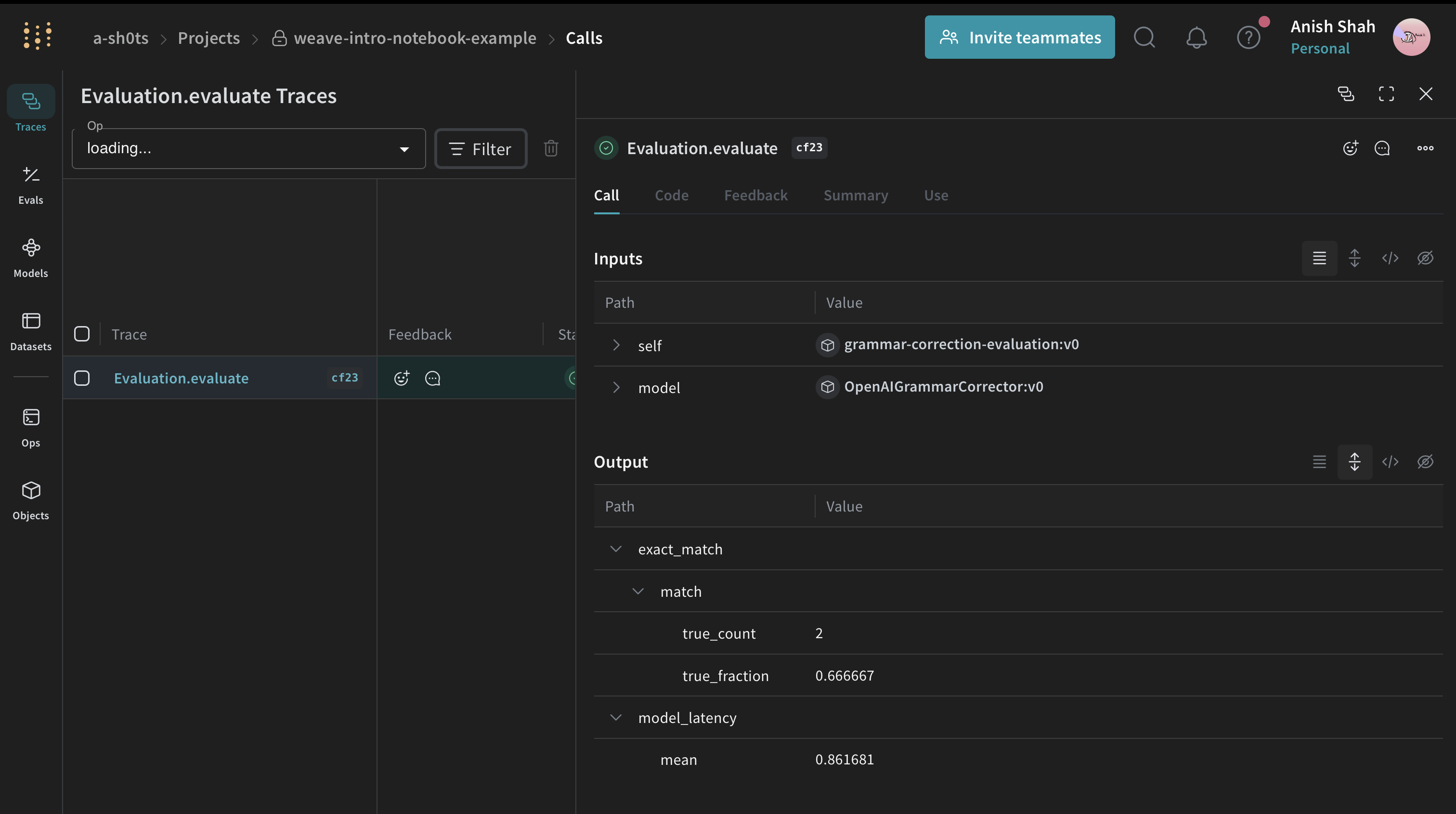
def exact_match(expected: str, output: dict) -> dict:
# Here is where you'd define the logic to score the model output
return {"match": expected == output}
# Score your examples using scoring functions
evaluation = Evaluation(
dataset=dataset, # can be a list of dictionaries or a weave.Dataset object
scorers=[exact_match], # can be a list of scoring functions
)
# Start tracking the evaluation
weave.init(PROJECT)
# Run the evaluation
summary = await evaluation.evaluate(corrector) # can be a model or simple function
What's next?
Follow the Build an Evaluation pipeline tutorial to learn more about Evaluation and begin iteratively improving your applications.